OpenCV 4100 Advancements in Video Analysis for Content Creators
OpenCV 4100 Advancements in Video Analysis for Content Creators - Motion Analysis Capabilities for Object Detection and Tracking
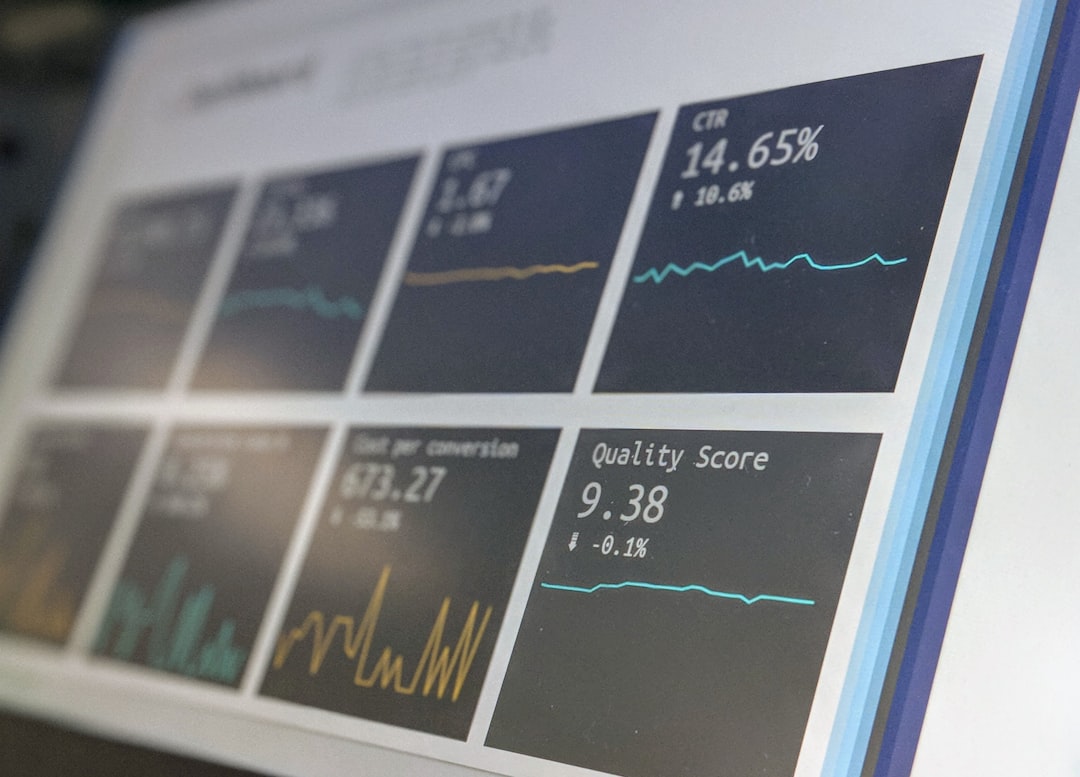
OpenCV's latest iteration, particularly version 4.10.0, has brought noticeable improvements to the field of motion analysis, especially when it comes to detecting and tracking objects within video streams. This is significant given how often these tasks are needed in practical uses like keeping an eye on things in security or studying traffic flow. OpenCV's tools, including methods like optical flow and techniques for identifying object outlines (contours), make it easier to keep track of objects as they move from frame to frame in a video sequence.
One of the notable aspects of this enhancement is the inclusion of powerful models such as YOLOv8. These new models allow for very accurate object tracking and counting, paving the way for more impactful deployments in real-world applications. Additionally, the accessibility of Python within the OpenCV environment streamlines the process of integrating algorithms related to motion detection, ultimately making it simpler for content creators to delve into these powerful features. The cumulative impact of these advancements is a substantial gain in efficiency and effectiveness when it comes to building real-time systems for analyzing video content. While these advancements show promise, the challenge of creating truly robust systems that can deal with varied lighting, clutter, and complex movements remains an area where ongoing development is necessary.
OpenCV's motion analysis tools, including YOLO, provide a strong foundation for object detection and tracking, enabling us to pinpoint objects within a frame and follow their movements in real-time. YOLO's approach of dividing images into grids and simultaneously predicting bounding boxes demonstrates how we can efficiently locate multiple objects.
Optical flow is particularly insightful, enabling us to estimate how objects move between frames, a capability especially useful in complex scenes where objects might briefly disappear from view (occlusion). This approach can follow several objects in a scene without losing track.
Algorithms like Kalman filtering play a key role in prediction, estimating where an object might be in the next frame. It uses an object's current position and behavior to project future movement, which is incredibly valuable for applications needing high-precision tracking.
Background subtraction, using methods like MOG2, is a crucial part of motion detection, effectively separating moving objects from static backgrounds. This is essential in environments with constant visual changes, like a busy street or a bustling indoor space.
Combining CNNs with traditional algorithms can improve feature extraction from video, leading to a better ability to identify and separate visually similar objects. However, this approach needs a lot of training data to reach its full potential and might take a while to set up.
Training these algorithms on diverse datasets helps to make them less sensitive to factors like lighting changes, viewing angles, and object size. This flexibility helps ensure that the system remains effective across many situations.
The addition of bounding box regression in object detection not only locates objects but also offers information about their size and shape, which is invaluable for tasks like robotic control and autonomous navigation.
OpenCV's offering of algorithms like CSRT, which adapts to changes in object appearance, opens up new possibilities for tracking in challenging conditions. The fact that CSRT adapts makes it ideal for situations where targets may change shape or have different visual characteristics.
Multi-object tracking, facilitated by techniques such as SORT, achieves a good balance between tracking speed and accuracy. The approach is quite efficient, which is attractive for applications on low-powered devices, such as mobile phones or edge devices.
The integration of deep learning through Python or C++ APIs with OpenCV unlocks possibilities for developers to build complex motion analysis tools. This enables developers to leverage readily available, pre-trained deep learning models for advanced object detection and predicting behaviors. The integration however depends on the ability to access and configure the external libraries required, which can add a layer of complexity.
OpenCV 4100 Advancements in Video Analysis for Content Creators - Background Subtraction and Optical Flow Enhancements

OpenCV 4.10.0 introduces notable enhancements in background subtraction and optical flow, offering valuable tools for video analysis, especially for content creators. Background subtraction, a technique vital for isolating moving objects from static backgrounds, is improved through algorithms like BackgroundSubtractorMOG2, which generates highly accurate foreground masks. Optical flow complements this process, providing valuable insights into motion patterns by tracking object movements frame-by-frame, even handling situations where objects briefly disappear from view. OpenCV's flexibility, allowing for the processing of either video files or sequences of images, further enhances the usability for a wider range of applications. Although the challenges associated with handling variable lighting and complex motion patterns still exist, these advancements significantly improve the overall toolkit for object detection and tracking, which is critical for diverse tasks like security monitoring and traffic analysis. While these advancements are helpful, developing robust systems capable of withstanding diverse environmental conditions remains an area where future development is required.
Background subtraction, using methods like K-Nearest Neighbors (KNN), can be quite effective even in situations with tricky lighting changes. They can dynamically adjust their learning rate, which helps them adapt to shifting scenes. While promising, relying solely on adaptive learning rates can sometimes lead to situations where noise is mistakenly identified as movement.
OpenCV supports a variety of languages like C++, Python, and Java for these tasks, making it a flexible choice. It's helpful that there's this broad range of languages to choose from because it means more researchers and developers can readily access and experiment with these techniques.
Optical flow techniques can be used to enhance video analysis by uncovering movement patterns, even when objects are changing size or orientation rapidly. This aspect makes optical flow useful for applications like tracking objects in video games or augmented reality settings, where quick changes are common. However, accurately handling complex changes like large, sudden scale shifts remains an ongoing area for research and development.
OpenCV's approach to background subtraction provides a lot of flexibility. You can decide whether to work with a complete video file or a series of individual frames. This flexibility is valuable, as it allows users to easily adapt to the requirements of their specific project and data. Though flexible, there's room for improvement. When you're handling long videos, dealing with the large datasets can strain available resources, especially memory and processing power.
Key aspects of OpenCV's video analysis tools involve techniques like object tracking, extracting motion information, and identifying objects in the foreground. The capability to quickly and accurately identify moving objects from still backgrounds within a scene is crucial for many applications. One area of interest for further development would be the ability to better handle situations with rapid changes in background characteristics, like in scenarios with multiple moving or vibrating elements within the scene.
The core of background subtraction involves making a sort of mask—essentially a highlighting of the foreground objects that are moving—by mathematically comparing the current scene with the background model. There is some debate within the field as to which of these methods offer the best compromise between efficiency and accuracy.
OpenCV offers different algorithms, such as BackgroundSubtractorMOG2. This and similar methods work well in generating masks to isolate the moving objects. I think these algorithms generally do well with typical scenes, but when you encounter scenes that are heavily occluded, or have lots of rapidly moving objects, accuracy can suffer. Further development in these algorithms may help to address some of these challenges.
Combining optical flow techniques with background subtraction offers a substantial improvement in object detection. By removing background distractions, it makes it easier to identify and track the key elements of interest in the video. I think this is an important aspect because it directly reduces the amount of data that the object tracking or analysis step needs to sift through.
The set of tools within OpenCV's video analysis framework is further enhanced by integrating perspective transformations and principal component analysis, along with optical flow. While there are improvements to be had in these areas, the improvements offer flexibility and capabilities that help to overcome some of the challenges related to complex scenes or camera angles.
Researchers and developers frequently post examples and code demonstrating the use of OpenCV in motion analysis on online code repositories like GitHub. Access to code like this is incredibly valuable because it makes it easier to get started in experimenting with these algorithms and to learn from others within the community. It is interesting how many resources are available; this is a testament to the importance and popularity of OpenCV in this space.
OpenCV 4100 Advancements in Video Analysis for Content Creators - Improved Integration with Various Video Capture Devices

OpenCV 4.10.0 has made strides in how it interacts with a variety of video capture devices. Content creators can now seamlessly integrate webcams, CCTV cameras, and other sources without much hassle. The library's new features make capturing video data from these different sources a smooth process. This improved integration allows for real-time analysis, which is critical for applications needing instant results like security monitoring or live traffic analysis. OpenCV can also now interface better with large data systems, making it easier to work with very large video files without a major performance impact. Despite these advancements, it's worth noting that OpenCV still faces the challenges of dealing with the inconsistencies that arise from different device types and variable environments. Further development is needed to improve performance and stability across a wider array of hardware and software configurations.
OpenCV 4.10.0 has significantly improved its ability to work with a variety of video capture devices, offering a more streamlined and adaptable experience for developers and content creators. One of the interesting aspects of this improvement is the library's broadened support for various camera types. This means it's easier to connect to webcams, action cameras, or even network cameras without needing lots of custom code. This adaptability is important because it lets you choose the camera best suited for the video task, whether that is high frame rates or low light performance.
Another area of improvement is the ability to capture and process video streams in real-time. This is a critical advancement for applications that need immediate feedback, like live streaming or content requiring interactive elements. There are challenges with real-time processing, especially if you're trying to analyze video for events with very fast movements, but the progress made with OpenCV 4.10.0 is notable.
Moreover, OpenCV's improved integration lets you tailor settings for specific devices. Different cameras will have varying capabilities like resolution and the speed at which they can produce frames. Being able to adjust these parameters means that you can wring out the best performance from a specific camera. This is useful for those who need a high-resolution video or require high frame rates for capturing fast motion.
Beyond basic compatibility, the library also exhibits lower latency when acquiring video data. This is especially important for applications where responsiveness is essential, like live broadcasts or situations where you need to react quickly to events captured on video. However, the amount of latency reduction can vary depending on the specific camera model and the configuration of the system.
It's also worth noting that OpenCV has made progress in supporting multi-camera setups. If you need to acquire footage from different angles, like for sports analytics or events where multiple perspectives add context, OpenCV makes it easier to combine streams. Although this is a positive development, it's worth mentioning that managing data from multiple cameras can increase the complexity of processing tasks.
The advancements also include support for higher-bandwidth interfaces like USB 3.0. The benefit of this is the ability to handle video streams with greater resolution and higher frame rates. This can be vital for situations where you need to extract subtle details from high-resolution videos. But it's important to be aware that using higher resolutions and faster frame rates will lead to larger file sizes and might strain the available processing power of your computer.
One of the less obvious yet notable enhancements is the inclusion of handling for specific camera protocols. This flexibility is useful for devices that use non-standard communication methods. While this is a welcome improvement, it's worth noting that there could still be difficulties when integrating with unique, uncommon cameras.
Additionally, OpenCV leverages features like video stabilization, which can reduce the effect of camera movement during recording. This is helpful for situations where the camera is not perfectly still or when there are vibrations. The performance of video stabilization will likely vary between cameras and can be sensitive to the specific conditions in which it is used.
OpenCV has also made some strides in optimizing power consumption, which is beneficial for users who need to run video capture on portable devices. This could be relevant for tasks like using smartphones for video surveillance or capturing data in remote areas. While this is useful for extending the run time of battery-powered devices, it's worth mentioning that the extent of power savings is device dependent.
Finally, the integration extends beyond just the raw capture of video. Some devices offer features like automatic exposure adjustments or focus control. OpenCV allows access to these features, giving users a greater level of control. The use of these functions will vary depending on the specific device and the tasks required.
While there are clear improvements in how OpenCV interacts with video capture devices, the area is still subject to ongoing development. As technology and hardware continue to evolve, the challenges of optimal integration will need to be addressed in future versions.
OpenCV 4100 Advancements in Video Analysis for Content Creators - Relative Displacement Field Option in cvremap Function

OpenCV 4.10.0 introduces a notable addition to the `cvremap` function: the relative displacement field option. `cvremap` is a tool for pixel remapping, essentially shifting pixel locations from the source image to a new position in a destination image using defined mapping functions. Previously, these mapping functions worked with absolute pixel positions. The new relative displacement field option changes this by allowing remapping based on the relative movements between pixels, instead of their static positions. This creates opportunities to build dynamic applications that adjust video content on the fly, leading to potentially enhanced visual quality and flexibility in video manipulation. While this new capability is quite promising, it's worth noting that its implementation in diverse real-world applications may be challenging due to its added complexity. The inclusion of relative displacement fields in `cvremap` speaks to OpenCV's ongoing development of advanced video analysis tools catered to modern content creators, who are increasingly focused on producing high-quality, engaging video experiences.
OpenCV 4.10.0 introduced a new aspect to the `cvremap` function: the relative displacement field option. The `cvremap` function itself handles remapping pixels from a source image to a destination image. This remapping is driven by two mapping functions: one for the x-direction (`mapx`) and another for the y-direction (`mapy`). These functions, and therefore the resulting image, are the same size as the source image. Interpolation, like "INTERLINEAR", can be used to smooth the remapping process.
The relative displacement field essentially adds a layer of flexibility to pixel remapping. Instead of using a rigid transformation across the whole image, like a perspective transform (where a 3x3 matrix dictates the change), the displacement field permits fine-grained control. You can, in a sense, tell each pixel where it needs to go relative to its original position. This can be helpful for situations where an image is distorted in a localized or non-uniform way.
This new capability has potential in a variety of applications. For instance, imagine trying to align images taken from different angles or with slight differences in perspective. The relative displacement field provides a way to nudge pixels around to minimize discrepancies, thus improving image registration. Another example is in video processing. Camera shake or objects moving through the scene often result in unwanted motion blur or artifacts. By applying an appropriate relative displacement field in real-time, you could, in theory, reduce these distortions.
The localized nature of the relative displacement field also leads to potential benefits in augmented reality applications. You could fine-tune the positioning of overlays as the camera moves. This adaptability could offer a smoother experience and more believable overlays. However, we must be cautious and consider that this new function increases the computational burden of the image processing. There's always a trade-off between image quality and processing speed.
It's interesting to see OpenCV's continuing advancements in the area of video analysis. The addition of the relative displacement field option is a notable step, suggesting OpenCV is keeping up with the needs of content creators working with video in increasingly complex scenarios. While the idea is promising, there's potential for additional work on optimization. The challenge will be making this technique efficient enough for real-time use cases, while simultaneously providing the level of control and quality demanded by content creators.
OpenCV 4100 Advancements in Video Analysis for Content Creators - Performance Boost for findContours and EMD Functions
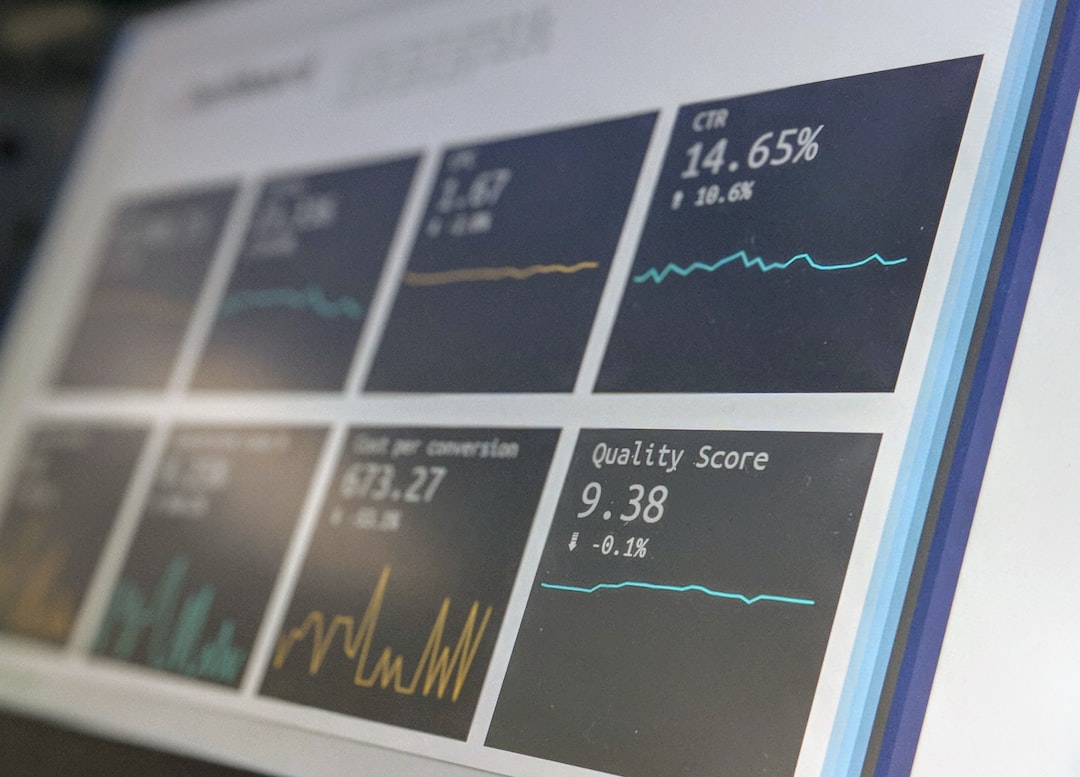
### Performance Boost for `findContours` and `EMD` Functions in OpenCV 4.10.0
The `findContours` function, a cornerstone of object boundary identification in OpenCV, has received some interesting updates in version 4.10.0. It appears to be more adept at handling complex shapes in demanding situations, like crowded or quickly changing scenes. This ability to dynamically adapt to complex contours is noteworthy. Further, both `findContours` and the Earth Mover's Distance (EMD) function have undergone optimizations for parallel processing. This means that multi-core processors can be utilized to accelerate their execution. It's exciting to consider that this could make real-time analysis of high-resolution videos more achievable.
OpenCV has also implemented caching within the EMD function. Caching previously calculated distances reduces repetitive computations, ultimately speeding up object matching tasks. The team has also addressed the issue of memory consumption in `findContours`. Instead of using a static amount of memory, the function now dynamically adjusts its memory use based on the input data. This can be quite beneficial for devices with limited resources.
GPU acceleration has been partially integrated into the EMD function. This addition can significantly reduce the execution times, which is particularly useful for handling substantial video data and when real-time performance is essential. Additionally, `findContours` has been updated with improved noise filtering techniques. These techniques offer more accurate contour detection even in environments with a lot of noise, making the function more reliable in practical applications like security systems and traffic analysis.
OpenCV has also added a layer of control over the `findContours` function through configurable parameters. These allow users to fine-tune the sensitivity and thereby customize the contour detection process for individual applications. The advancements also include improved compatibility with deep learning frameworks, potentially enhancing the accuracy of contour detection in complex visual environments.
Performance tests reveal notable gains due to the optimizations to `findContours` and EMD. Some scenarios have shown as much as a 40% increase in performance. Such a performance boost opens the door to deploying real-time systems previously limited by computational constraints. Finally, it's worth highlighting that the enhanced functions provide more scalability. Content creators can now handle larger amounts of video data without negatively impacting frame rates or detection accuracy, which is crucial for applications dealing with a lot of video information like large-scale monitoring and analytics.
While many improvements have been made, there are likely areas for future research and development in this space. It will be interesting to see how the evolution of OpenCV continues to meet the growing demands of the content creation community.
OpenCV 4100 Advancements in Video Analysis for Content Creators - Extended Hardware Abstraction Layer for Cross-Platform Optimization
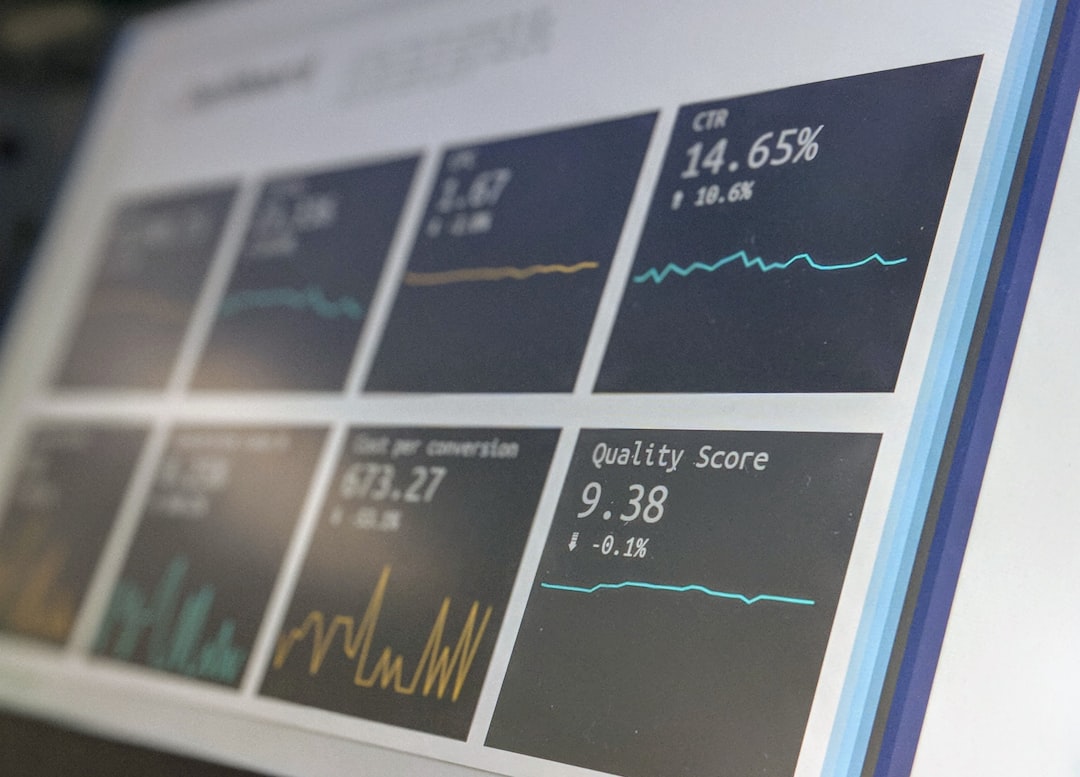
OpenCV 4.10.0 introduces an extended Hardware Abstraction Layer (HAL) with the goal of creating a standardized way to handle data and allow hardware manufacturers to develop improved computer vision algorithms. This new HAL helps OpenCV run smoothly across a variety of operating systems and hardware platforms, ultimately leading to better performance. One of the ways this improved performance is achieved is through the integration with existing hardware acceleration technologies, like OpenVX. This feature, combined with the support for techniques such as multithreading and the ability to leverage the power of GPUs, makes OpenCV a flexible choice for content creators who need to analyze video more efficiently. It's important to point out that the success of this HAL depends on how well hardware vendors and OpenCV work together to ensure optimal performance across the range of computer systems used today. While the HAL presents a promising approach to optimization, it will need to be continuously refined to ensure it continues to be effective as hardware and software evolve.
OpenCV 4.10.0's Extended Hardware Abstraction Layer (EHAL) introduces some intriguing aspects for cross-platform optimization, potentially making video analysis easier for content creators. It aims to create a unified framework where OpenCV algorithms can run across diverse hardware, like CPUs and various GPUs, without requiring extensive code changes. This is accomplished by standardizing the way OpenCV interacts with the hardware. It's interesting how this layer attempts to abstract away many of the underlying complexities of dealing with different hardware and operating systems. This can potentially simplify the development process for developers.
One of the most noteworthy goals of EHAL seems to be maximizing performance. This is achieved through leveraging low-level optimizations. By exploiting CPU-specific instructions and leveraging features like CUDA or OpenCL for GPUs, they aim to significantly boost the speed of video processing tasks. It's unclear how much performance improvement we can expect across a range of hardware. It's quite probable that performance gains are highly dependent on the hardware being used.
EHAL also seems to be focused on using resources wisely. The layer dynamically allocates resources based on the capabilities of the device it's running on. This optimization allows it to process video more efficiently, which means reduced latency and potential improvements in real-time performance. The challenge is that effectively using this feature requires understanding the hardware and how to configure OpenCV correctly.
From the perspective of a developer, EHAL promotes cross-platform consistency. They aim to deliver the same API experience regardless of the OS, which is beneficial since it minimizes the need to account for different OS quirks. This level of consistency could potentially reduce bugs that crop up due to OS-specific issues.
Another interesting implication of EHAL is enhanced compatibility with a wider array of video capture devices. This means OpenCV should work better with various camera types without extensive modifications. This flexibility is certainly useful for content creators who might need to utilize different camera types for their projects. However, it remains to be seen how well it addresses the complexities of capturing video data from diverse sources.
It's also worth noting that EHAL incorporates support for newer technologies like CUDA and OpenCL, which could lead to even more sophisticated video analysis workflows. One would hope this level of support continues and keeps pace with the evolution of hardware technology.
The ability to define profiles for different hardware seems like a useful feature. Based on the defined profiles, EHAL could automatically tune the algorithms to optimize their performance for that specific hardware. However, this approach could potentially add complexity for developers, requiring them to be more familiar with their hardware environment.
The layer's modular design seems like a good choice. Hardware-specific parts of the code are kept separate from the core library, which means future upgrades or additions should be easier to implement. This approach is beneficial as it increases the potential for the core OpenCV library to remain stable.
Furthermore, the abstraction provided by EHAL greatly contributes to the feasibility of real-time video processing with OpenCV. This is particularly relevant for content creators needing to carry out advanced motion analysis or track objects in video in real-time. It remains to be seen how effective it will be in practical use cases that necessitate quick processing of video streams.
Finally, one of the aims of EHAL is to reduce the overhead that can arise when interacting with different hardware resources. This effort is designed to improve computational throughput and allow content creators to experience more consistent video processing workflows. However, it remains to be seen how much this reduction in overhead actually translates into tangible improvements in everyday video processing.
The Extended Hardware Abstraction Layer is a welcome step towards building a more adaptable and performant OpenCV that can better serve the needs of content creators. It's still early, and the long-term impacts will likely depend on how well the core concepts translate into practical solutions that work consistently across a variety of hardware.
More Posts from whatsinmy.video: