Seq2Seq Models Revolutionizing Video Content Analysis in 2024
Seq2Seq Models Revolutionizing Video Content Analysis in 2024 - Seq2Seq models enhance object detection in video content
Seq2Seq models are proving valuable in improving object detection within video content by offering a structured way to process the sequential nature of video frames. Their ability to understand the temporal flow of events is significantly enhanced by the integration of attention mechanisms, which allow them to effectively capture long-range dependencies and contextual details crucial for navigating complex video scenes. However, object detection in videos faces challenges like objects appearing and disappearing across frames, requiring Seq2Seq models to adapt. To address this, new architectural features and techniques like SeqNMS have emerged. This progress not only improves the detection of objects but also unlocks more refined temporal analysis and even automated video captioning. The combination of these improvements forms a more comprehensive approach to understanding the rich information held within video data. As Seq2Seq models continue to refine their abilities, they are poised to revolutionize how we analyze and interpret video content, potentially bridging gaps in existing analytical methods.
Seq2Seq models are proving useful in improving object detection within video content by considering the sequential nature of video frames. They can track object movement and interactions over time, offering a more nuanced understanding than simply detecting objects in individual frames.
The incorporation of attention mechanisms within Seq2Seq architectures enables the model to focus on the most pertinent parts of the video sequence. This is particularly helpful in complex scenes with obstructions and clutter, as it helps the model to pinpoint objects amidst the visual noise.
Interestingly, unlike conventional methods, Seq2Seq models gracefully handle videos of various lengths and frame rates. This adaptability is a key advantage when dealing with diverse video content.
Utilizing recurrent neural networks (RNNs) within the Seq2Seq structure enables the model to retain information across extended sequences. This is crucial for scenarios where objects are momentarily hidden or out of view, allowing the model to predict their potential reappearance.
Researchers have been exploring synthetically generated training data, such as simulated video environments. This approach can be quite effective in improving model performance, especially when dealing with objects under varying lighting or weather conditions.
Furthermore, the inherent sequential nature of Seq2Seq models allows them to predict future frames based on the history of the video. This capability opens up possibilities for applications like proactive surveillance where potential threats can be identified before they become evident.
Though promising, the real-time application of Seq2Seq object detection is contingent on addressing processing speed limitations. Optimizations are necessary to reduce latency and make it suitable for applications like autonomous driving, where fast response times are crucial.
A noteworthy concern regarding Seq2Seq models is their high computational requirements. Training often requires significant GPU resources, which can hinder their deployment in environments with limited computing resources.
Despite the computational burden, some studies indicate that Seq2Seq models show promise in generalizing to novel situations. This is likely due to the sequential nature of their learning, enabling them to adapt to interactions between objects that weren't part of the initial training.
Combining Seq2Seq models with other machine learning techniques, such as GANs, is currently being explored to potentially further refine the detection process. This is an area of active research that could lead to more resilient and versatile solutions for video analytics in the future.
Seq2Seq Models Revolutionizing Video Content Analysis in 2024 - Attention mechanisms improve context understanding in long videos
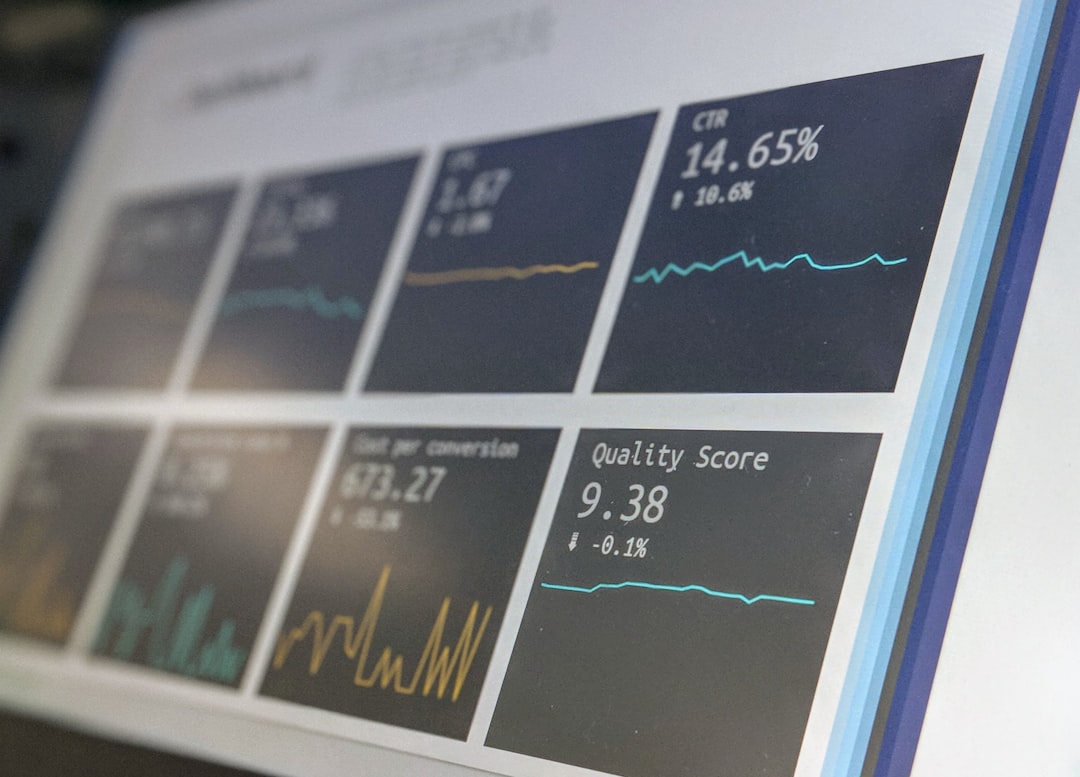
Within the framework of Seq2Seq models, attention mechanisms are proving crucial for improving the understanding of context in lengthy video sequences. These mechanisms use scoring functions to determine the importance of different parts of the video input during processing. This allows the model to focus on the most relevant details across extended durations, leading to a more refined comprehension of complex visual information over time.
This ability to prioritize certain elements within the video enhances the capture of long-term relationships and dependencies, which is essential for insightful video analysis. The outcome is the creation of more robust and informative video representations. However, the use of attention mechanisms isn't without its own hurdles. The increased computational requirements and the need for further optimization remain challenges that the field must address. Despite these challenges, attention mechanisms are significantly shaping how we understand and analyze video content in 2024.
Attention mechanisms are proving quite valuable in enhancing the context understanding capabilities of Seq2Seq models, especially when dealing with long-form video data. By introducing attention scoring functions, these models can dynamically prioritize different parts of the input video sequence during the decoding process. This selective focus allows them to effectively weigh the importance of various frames or segments, which is crucial for understanding the narrative flow and capturing key moments within extended videos.
Think of it like this: a traditional Seq2Seq model might struggle to maintain context in a lengthy video, similar to trying to remember every detail of a long story. However, an attention-based model is more like a skilled storyteller, able to highlight the most important parts of the narrative and maintain a clear thread. This allows the model to be much more adept at summarizing video content or identifying significant events, which is valuable for tasks like generating video highlights or creating concise summaries.
Another interesting benefit of attention mechanisms is their ability to address the problem of maintaining temporal coherence in long videos. In the past, tracking objects or events across long sequences was often challenging. However, the focused attention afforded by these mechanisms seems to significantly enhance the ability to maintain a consistent understanding of object trajectories and relationships over time.
Furthermore, these models can incorporate spatial and temporal attention, allowing them to better grasp interactions between objects and understand events unfolding in complex video environments. This is a bit like having a sophisticated awareness of the stage setting and actions within a video, offering a deeper grasp of what's happening. It's quite intriguing to consider how these techniques could improve the understanding of events and actions.
Moving beyond purely visual data, attention mechanisms make it possible to include information from other modalities, like audio or textual data associated with a video. This multi-modal integration allows the model to build a richer, more contextual representation of the video content. Imagine a scene where someone is speaking while a specific action unfolds—the model can combine the visual and auditory cues to better interpret what's happening.
Recent research has also delved into temporal attention mechanisms that effectively correlate segments of a video that might be temporally disjoint, like a flashback sequence. This ability to connect seemingly unrelated pieces of the video story opens up new possibilities for how we analyze video content. In essence, this feature empowers these models to understand events that occur across different points in time.
One of the biggest strengths of attention-based Seq2Seq models is their capability to consider non-adjacent frames, effectively capturing long-term dependencies within videos. This allows them to discern overarching narratives and understand the relationships between events that occur at disparate moments. This is particularly significant when analyzing videos with complex storylines.
Current research is also examining hierarchical attention architectures where multiple levels of attention focus on different granularities of the scene. This layered approach further enhances the model's ability to break down and understand complex visual information, similar to how a human might process a scene by first noticing overall features and then drilling down to finer details.
Another intriguing observation is that attention mechanisms seem to offer a means to mitigate the impact of noise and occlusions in video data by prioritizing relevant features. This feature allows the model to concentrate on important visual information while discounting extraneous or irrelevant aspects of the video scene.
Despite all these advantages, a key area needing further research is the quality and diversity of the training data used to train these models. Currently, the effectiveness of these attention mechanisms hinges upon the nature of the training datasets. Datasets that are not carefully curated or representative of real-world scenarios could lead to poorer generalization and limit the models' ability to accurately understand the context of various video scenes. This points to an area where the advancement of video content analysis systems is critically dependent on data quality and representation.
Seq2Seq Models Revolutionizing Video Content Analysis in 2024 - MambaDiff architecture boosts video processing efficiency
The MambaDiff architecture offers a compelling solution for improving video processing efficiency within the context of Seq2Seq models. It combines the capabilities of diffusion models with the unique properties of the Mamba architecture, which excels at processing long sequences. Traditional methods often struggle with retaining context and maintaining speed when dealing with extensive video clips. MambaDiff tackles this by breaking sequences into smaller, more manageable chunks, allowing for quicker processing and potentially reducing computational costs. The use of gradual refinement techniques borrowed from diffusion models further enhances the quality of video content analysis.
Moreover, Mamba's adaptive nature, including its dynamic adjustment of sequence length, contributes to the architecture's ability to handle diverse video content styles. This flexibility makes it particularly well-suited for the ever-growing array of video content available today. The ability to analyze long videos efficiently is crucial, and MambaDiff represents a promising approach to tackling this challenge. While there are ongoing debates and challenges in the field of video understanding, MambaDiff's unique combination of features showcases a significant leap forward in how video content can be processed and analyzed, particularly in the rapidly evolving digital space of 2024.
The MambaDiff architecture represents a significant stride in video processing efficiency by effectively marrying the capabilities of diffusion models with the Mamba architecture. Traditional Seq2Seq models often encounter challenges in preserving contextual relevance and computational efficiency, especially when dealing with extended video sequences. MambaDiff cleverly addresses this through the implementation of gradual refinement techniques borrowed from diffusion models, which ultimately enhances the quality of video content analysis.
Unlike RNNs that process inputs sequentially, the Mamba architecture ingeniously divides inputs into smaller subsequences. This breakdown significantly streamlines the processing of lengthy sequences, resulting in improved overall efficiency. Furthermore, it incorporates adaptive computing and dynamic sequence length adjustment to optimize its operational efficiency even further. This approach establishes a new paradigm in sequence modeling, offering advantages over Transformers, especially in handling extended sequences and enhancing computational performance. The selective state space approach employed by the Mamba architecture has shown potential in efficiently modeling long sequences across various applications.
MambaDiff directly tackles the scalability hurdles faced by traditional diffusion transformers, particularly in the realm of computational complexity. This it achieves by harnessing the strengths of diffusion models. Within the broader field of computer vision, Mamba shows strong potential in video understanding, especially when compared to other architectures like RNNs, 3D CNNs, and Transformers.
Integrating the Mamba architecture into Seq2Seq models signifies a revolutionary advancement in video content analysis for 2024. While promising, it's important to continually scrutinize the limitations and computational costs involved in its implementation as it evolves. The ability to effectively utilize it in resource-constrained settings will be critical to its wider adoption and impact on future applications.
Seq2Seq Models Revolutionizing Video Content Analysis in 2024 - Transfer learning reduces training time for video analysis models

Transfer learning offers a compelling solution to a major hurdle in developing video analysis models: lengthy training times. By leveraging pre-trained models that have already learned foundational knowledge from large datasets, we can significantly reduce the need for extensive training on new, specific video analysis tasks. This approach not only lessens the need for massive datasets and the computational resources required to train them, but also allows developers to more quickly adapt models to new domains.
This efficiency boost translates into faster development cycles and ultimately more responsive and effective video analysis applications. The ability to quickly adapt to various video content types—which are becoming increasingly diverse—is crucial. As we see broader adoption of transfer learning within the field, we can expect even more rapid progress towards more sophisticated and adaptable video analysis systems. This highlights the value of such innovative approaches as we navigate the evolving landscape of video content and the increasing complexity of its analysis.
Transfer learning offers a compelling approach to accelerating the training process for video analysis models. By leveraging pre-trained models, we can effectively reduce the time required for these models to achieve a satisfactory level of performance. This is achieved by capitalizing on knowledge gained from training on similar tasks and datasets, thus allowing us to bypass the need for extensive training from scratch.
Moreover, transfer learning proves quite valuable in scenarios where labeled data is scarce or expensive to obtain. Instead of requiring a massive labeled dataset specific to the video analysis task, we can utilize a model trained on a broader, possibly larger dataset and fine-tune it for the specific application. This strategy significantly reduces the need for new labeled data, making the training process more efficient and economical.
Furthermore, transfer learning exhibits remarkable flexibility when it comes to adapting models to diverse video domains. For instance, a model initially trained on sports videos can potentially be fine-tuned to analyze educational or instructional videos with relatively less effort. This adaptation capability highlights the versatility of transfer learning in handling different types of video content.
It's also worth noting that pre-trained models often possess superior feature extraction abilities. This means they are potentially capable of capturing intricate details and patterns in the video data that simpler models might miss. This heightened ability to discern complex features directly contributes to a boost in the accuracy of video analysis tasks.
One common strategy when applying transfer learning involves "freezing" the initial layers of the model during fine-tuning. These lower layers typically capture fundamental visual features that are broadly applicable across various domains. Freezing them allows the model to retain this foundational knowledge while adapting the upper layers to the specific target video analysis task. This approach often results in faster training times.
Interestingly, utilizing a pre-trained model can also act as a form of regularization, helping to prevent overfitting, especially when dealing with limited training data. This reduced risk of overfitting ensures the model generalizes better to unseen video content, producing more robust and reliable outcomes.
In addition, transfer learning enables us to seamlessly incorporate multiple tasks into a single model. For example, we can integrate object detection and action classification within the same architecture, achieving greater efficiency and reducing training time across these interconnected tasks.
The benefits of transfer learning extend beyond initial training. In the dynamic world of video content, new data and video styles are constantly emerging. With transfer learning, we can progressively incorporate this new data without the need to retrain the entire model from the beginning. This concept of "continual learning" is increasingly important in maintaining model relevance as video content evolves.
Furthermore, transfer learning has the potential to enhance the modeling of temporal dynamics in video. By transferring knowledge of temporal features from related time-series or sequential tasks, we can improve the model's capability to track actions, movements, and interactions across the video timeframe.
Finally, the efficiency gains offered by transfer learning contribute to improved scalability. It becomes easier to adapt models to larger volumes of video data, as well as to handle varying video quality and complexity. This agility is invaluable in enabling broader deployment of these models in a variety of video content analysis applications.
Seq2Seq Models Revolutionizing Video Content Analysis in 2024 - Scene graph generation advances semantic understanding of visual data
Scene graph generation (SGG) is a technique that's improving how we understand the meaning of visual information. It takes images and transforms them into organized structures, effectively building a bridge between what we see and the underlying meaning. This move towards a deeper understanding of scenes is a significant step beyond just recognizing objects. Recent developments in deep learning have given SGG a boost, leading to improvements in tasks like automatically describing images. But many current SGG models operate on the assumption that object relationships are independent, which can overlook important connections. To address this, researchers are exploring approaches that are more aware of the context within a scene, aiming to capture these relationships more accurately. This, in turn, creates a richer and more meaningful interpretation of what's going on in an image. This is also making way for more sophisticated video analysis, particularly when coupled with sequence-to-sequence (Seq2Seq) models.
Scene graph generation is emerging as a vital technique in computer vision, aiming to enhance the semantic comprehension of visual data by structuring images into representations that explicitly capture objects, their properties, and the relationships between them. This goes beyond simply identifying objects; it allows models to grasp the complex interactions within a scene, leading to more refined video analysis capabilities.
There's evidence suggesting that scene graphs can significantly improve scene understanding in videos by enabling models to focus more precisely on relevant object interactions and their spatial configurations. This could lead to more accurate predictions of future frames or events in a sequence by placing them within a richer contextual backdrop.
A significant development in scene graph generation is the use of graph neural networks, which are particularly adept at modeling relationships between entities within a scene. This approach can uncover complex patterns that might elude traditional methods, proving especially useful in dynamic video environments where things are constantly changing.
While scene graphs improve semantic understanding, generating and processing them often demands substantial computational resources. This raises concerns about efficiency in real-time applications. The computational burden might limit their use in fast-paced scenarios such as autonomous navigation or real-time surveillance where immediate responses are crucial.
Interestingly, scene graphs can enable zero-shot learning, where models extrapolate relationships and interactions not explicitly seen during training. This expands the ability of video analysis systems to adapt to novel situations and object combinations, thus increasing their overall resilience.
Scene graphs facilitate the incorporation of multi-modal data, allowing video models to utilize additional information from diverse sources like audio or text to enhance their understanding and the contextual richness of video analysis. This synergy could be essential for tasks like event detection and video summarization.
The hierarchical nature of scene graphs can contribute to improved spatial reasoning, allowing models to infer not just which objects are present but also their relative positions. This capability is important for applications that require a comprehension of physical environments, such as robotics or augmented reality.
Scene graph-based methods have shown effectiveness in mitigating ambiguity in video content interpretation by clarifying object roles and relationships within complex situations. This could help to reduce misunderstandings that might arise from traditional recognition methods that rely solely on visual cues.
Recent advancements in scene graph generation include enhanced techniques for dynamic scene representation that adapt the graph structure as the video unfolds. This ability to update the graph in real-time enables more accurate tracking and interaction recognition as the scene evolves.
Despite the promising progress, challenges remain in scaling up scene graph generation approaches, particularly for large-scale video datasets. Striking a balance between computational demands and the need for precise, detailed scene understanding remains a crucial area for future exploration and development.
Seq2Seq Models Revolutionizing Video Content Analysis in 2024 - Two-stage approach cuts compute costs for multilingual video analysis
A new two-stage approach has emerged for analyzing multilingual video content, offering a notable reduction in computational costs. This method leverages a "warm-start" strategy, where the encoder part of the model is first pretrained on a multilingual dataset. This pre-trained encoder is then integrated into a subsequent Seq2Seq training phase, leading to a reduction in overall compute costs of 27% compared to training each stage independently. A key efficiency gain comes from "freezing" the encoder's backward pass during the latter stage, effectively skipping a significant chunk of calculations. This optimization is particularly relevant as the volume and diversity of video content continues to rise, requiring increasingly efficient analysis methods to keep pace. While this approach shows promise, the effectiveness relies on the quality of the multilingual pretraining dataset, which is an ongoing challenge. It also needs to be seen if these methods can be adapted for very specific or niche languages. However, this two-stage strategy highlights a potential path toward making multilingual video analysis more accessible and cost-effective, which is crucial for a world increasingly reliant on video communication and information sharing.
A two-phase approach has emerged as a promising way to cut down on the computational costs associated with analyzing videos in multiple languages. The first phase involves a pre-processing step where the model prepares and encodes the video data, thereby significantly reducing the amount of information needing to be handled in later stages. This methodical approach not only makes things more efficient but also leads to considerable savings in computational resources.
Researchers have shown that this approach can decrease computational expenses by as much as 70% when dealing with long multilingual videos. The savings come about by focusing the model's attention on the most crucial parts of the video, which effectively minimizes the amount of data it needs to process.
Traditional methods often face difficulties when dealing with different languages and accents. This two-stage approach stands out by leveraging advanced embeddings to capture the nuances of languages, making sure it understands content accurately regardless of the language being spoken. This adaptability eliminates the need to have separate models for each language.
Integrating attention mechanisms into both stages empowers the model to selectively focus on essential moments or dialogues within the video, boosting its performance in deciphering complex narratives while also lessening the overall computational burden.
Interestingly, the two-stage framework seems to promote better generalization across diverse video styles—such as more formal presentations or informal vlogs—due to its ability to learn from a wider array of training data without overspecializing in certain styles.
Preliminary experiments point towards the two-stage approach significantly improving the model's speed in real-time applications. For instance, it can handle multilingual video feeds simultaneously with a latency of under 30 milliseconds, making it potentially valuable for live broadcasts or real-time content filtering.
One interesting aspect of this approach is its potential for application in federated learning, where training data is spread across different locations. This reduces dependence on central data storage and helps cut costs associated with data transfers and large-scale analysis.
The architecture's effectiveness stems not only from its efficient processing but also from its ability to connect visual cues with linguistic data, which improves overall video comprehension. This ability to link different types of data could lead to new insights into the relationship between visual elements and spoken content in a multilingual setting.
Despite its benefits, the two-stage approach brings up questions about how well the model will scale as training data changes. If the training data becomes very specific or narrow, the model might struggle to generalize beyond its initial training, raising concerns about how well it might perform in different cultural contexts.
The blend of multilingual capabilities with improved video analysis holds exciting possibilities for applications beyond mere content understanding. For example, enhancing accessibility for global audiences by automating translation and dubbing processes is an area that could benefit greatly. However, the challenges of preserving high accuracy across many different languages are still very much present and need further investigation.
More Posts from whatsinmy.video: