Creating Dynamic Tables in Python A Step-by-Step Guide Using Pandas for Video Analysis Data
Creating Dynamic Tables in Python A Step-by-Step Guide Using Pandas for Video Analysis Data - Importing Pandas and Loading Video Analysis Data
To begin analyzing video data with Python, you first need Pandas. Import it using `import pandas as pd`. With Pandas loaded, you can readily bring your video data into a DataFrame from various sources. Common sources include CSV files and Excel spreadsheets, which can be handled using functions like `pd.read_csv()` and `pd.read_excel()`. Pandas DataFrames provide a versatile platform for working with your data. They allow for straightforward operations such as filtering, indexing, and restructuring your data. This ability to manipulate data is vital for constructing dynamic tables and conducting in-depth analysis of video metrics. These DataFrames are then ready for advanced techniques like grouping (`groupby`) and pivoting (`pivot_table`) for more complex data aggregation. Remember, data quality plays a key role. It's essential to clean and organize your video data before proceeding to more intricate analysis, which can lead to improved accuracy and deeper insights.
1. Pandas, with its ability to handle large datasets efficiently, is a valuable tool when working with video analysis data, especially when dealing with the large number of timestamps, frame data, and associated metrics involved in a typical analysis. While the speed is appealing, researchers need to be mindful of potential bottlenecks in loading and manipulating large video datasets.
2. Loading video data directly into Pandas can be an efficient way to analyze data in real time. However, relying on lower-level libraries for this often involves significant coding effort and could limit portability across different video file formats. Whether this approach is worth the development effort depends on the specific analysis goals.
3. Pandas is particularly adept at handling time-series data, making it a suitable choice for video analysis, where frame-based metrics evolve over time. This means tasks such as resampling data or calculating rolling averages, which are common in video analysis, become straightforward. Nevertheless, applying sophisticated time-series models may require using dedicated time series libraries.
4. The vectorized operations offered by Pandas are crucial for speeding up video analysis. Instead of painstakingly looping through each frame, you can apply operations to entire columns of data, significantly accelerating the analysis process. However, being aware of memory usage is important as vectorized operations might increase memory demands, especially with larger datasets.
5. Using intermediate formats like CSV or Excel when loading video data into Pandas offers a structured approach for handling metadata and facilitates analysis. However, for very large datasets, these formats can become cumbersome due to size and the potential for data loss or inconsistencies during conversion.
6. Newer formats like HDF5 can address the scalability issues associated with large video analysis datasets by enabling efficient storage and retrieval. This is particularly helpful when complex queries are required. Though these specialized formats require specific libraries and understanding, the benefits in terms of data management and performance are substantial.
7. Visualizing data is a critical part of understanding video analysis results. Pandas integrates seamlessly with visualization libraries, enabling immediate visualization of processed data. This facilitates insightful interpretation of complex datasets, but the user needs to be careful not to misinterpret visualizations, especially when dealing with potentially biased data.
8. Pandas DataFrames' inherent labeling capability is very useful for organizing and retrieving video frame information based on timestamps and other identifiers. This streamlining of the analysis workflow is particularly helpful for navigating and filtering through large amounts of data. Yet, defining an efficient labeling system beforehand is vital for effective analysis.
9. Filtering video segments using Boolean indexing in a Pandas DataFrame is a powerful technique to focus on specific events or content changes in a video. However, defining effective filtering criteria can be tricky and needs a good understanding of the video's contents. Overly restrictive criteria can lead to incomplete results.
10. The ability to combine video analysis with Pandas paves the way for employing machine learning algorithms directly on the data. This enables automation of insights and predictions, leveraging historical analysis to gain a better understanding of the content and events captured in the video. But this should be done with caution, and models must be properly validated to avoid bias or faulty inferences.
Creating Dynamic Tables in Python A Step-by-Step Guide Using Pandas for Video Analysis Data - Creating a DataFrame Structure for Easy Manipulation

When analyzing video data, structuring your data effectively within a Pandas DataFrame is crucial for efficient manipulation. DataFrames, being two-dimensional tables, simplify common data operations like indexing, filtering, and summarizing your data. This makes it easy to build the foundation for creating dynamic tables tailored to your analysis needs. Furthermore, Pandas offers powerful tools like `pivot_table()` and `groupby()` to help summarize and categorize data in more intricate ways, a key element for extracting valuable insights from your video metrics. However, it's important to acknowledge potential performance limitations that can arise when dealing with very large datasets. Organizing the DataFrame effectively by using meaningful labels and indexes is helpful for easily accessing data. But ensure your filtering criteria are well-defined to prevent generating incomplete or biased conclusions during analysis.
Pandas DataFrames offer a flexible way to handle video data, letting you explore different facets of the same dataset without creating multiple copies. This is really useful when you're trying to understand various video metrics at once, saving memory and making things more efficient. However, managing multiple views of data requires careful planning and attention to avoid confusion and unintended data duplication.
The `melt` function in Pandas lets you switch your DataFrame from a wide format to a long format. This can be helpful for certain types of analysis. However, be aware that excessive use can lead to convoluted data structures that may be hard to work with, especially if you're not used to this type of reshaped data.
Pandas supports hierarchical indexing (multi-indexing), which is handy for representing intricate relationships within your video data, such as the interplay between timestamps, frame numbers, and events. While it gives you a really organized structure for several levels of data detail, it can also introduce complexities that make debugging and data retrieval more challenging.
You can connect Pandas with SQL databases for more sophisticated data retrieval techniques. This is extremely valuable when dealing with extremely large video datasets that require optimized querying. But it's important to maintain data synchronization between the SQL database and your DataFrame carefully to avoid inconsistencies and potential errors.
The `query` method in Pandas offers a more intuitive way to filter your data using strings. This can make data filtering a lot easier and clearer. But, if not properly validated, it can lead to unanticipated results if not validated correctly.
The `pivot_table` function allows you to restructure your data to gain more nuanced insights into the multi-dimensional aspects of video analysis, for instance, when you're comparing different metrics across various video clips. This is a powerful tool but, using pivot tables too much can obscure the original data organization, potentially causing you to lose track of where the data came from.
When dealing with large datasets, the `apply` method in Pandas can become a performance bottleneck if not used carefully. Generally, it's more efficient to utilize the built-in operations for better performance during video analysis. However, this can require rethinking your approach to leverage these built-in functions.
The `groupby` method is helpful for summarizing video metrics, but it can also lead to performance problems if not implemented carefully. Complex grouping operations on substantial datasets can cause analysis to slow down, necessitating careful consideration of your grouping strategy.
DataFrames have ways to handle missing values effectively using functions like `fillna()` and `dropna()`. This is essential for real-world video analysis data which frequently includes gaps or incomplete information. But, the way you choose to deal with missing values can have a significant impact on the validity of your analysis. It's crucial to be aware of this.
When combining multiple DataFrames to incorporate diverse video metrics, understanding how to correctly use the `merge` function is essential. If you don't use it right, you could introduce duplicate information or create issues with data integrity. Making sure that the keys across your DataFrames are consistent is crucial to guarantee the reliability of your analysis.
Creating Dynamic Tables in Python A Step-by-Step Guide Using Pandas for Video Analysis Data - Using groupby() for Aggregating Video Metrics
Pandas' `groupby()` function is a core tool for summarizing video metrics. It lets you categorize your data based on certain characteristics (like video titles, upload dates, or user demographics) and then apply various summary calculations. This is particularly useful when working with metrics like how many times a video was watched, how long people watched, or how often viewers interacted with it.
You can get even more out of your analysis by using the `agg()` method with `groupby()`. This lets you calculate multiple metrics at once for different parts of your data. Additionally, you can use `groupby()` with `pivot_table()` to build dynamic tables, helping you understand how video performance varies across different factors.
While very helpful, keep in mind that overusing complex `groupby()` operations, especially with large datasets, can impact the speed of your analysis. This means being mindful of how you organize your grouping process to optimize the analysis workflow.
Pandas' `groupby()` function offers a powerful way to aggregate video metrics, allowing us to analyze viewer behavior on a larger scale. For instance, we can use it to calculate the average view count for different time periods, which can reveal patterns in how viewers interact with videos.
Using `groupby()`, we can apply multiple aggregation functions at once, such as calculating the mean, count, and standard deviation of viewership data. This approach can significantly speed up our analysis by combining multiple operations into a single step, which is a plus compared to running separate commands.
The `groupby()` function can also be used for time-based aggregation. This means we can easily summarize video metrics for each hour, day, or month, which is great for identifying trends and seasonality in viewer engagement. Without this, uncovering such temporal patterns would be more challenging.
Furthermore, `groupby()` handles hierarchical data very well. This lets us analyze video metrics on multiple levels, like looking at performance by channel, video type, or publishing date. This ability to group at different levels is really helpful, and doing so with `groupby()` avoids the need to constantly reshape the entire dataset, which would be both complex and slow.
However, `groupby()` has some drawbacks. When we use it, we lose the original DataFrame structure, which can be problematic if we need to go back to the original layout. We need to carefully plan when and how we want to reset the index if we require the original data layout again for visualization or more analysis.
When working with large datasets, `groupby()` can consume substantial memory resources. We have to consider this and plan how to manage it. Optimization techniques, such as splitting the data into smaller chunks (chunking), can prevent the system from slowing down due to excessive memory demands.
Analyzing video data with `groupby()` also makes it easier to detect outliers and unusual events. We can compare grouped metrics to gain a clearer understanding of sudden jumps or drops in engagement, which is very helpful in guiding content strategy and targeting decisions.
The `agg()` method works really well with `groupby()` to allow custom aggregation functions. This feature is particularly useful for unique video metrics that don't have standard aggregation methods, like calculating the median view duration or building custom metrics based on specific user interactions with the video.
Another advantage of `groupby()` is that it supports grouping data based on multiple keys. This means that we can aggregate metrics by combining multiple attributes, such as video genre and release date. Such multi-key grouping is very helpful in providing more in-depth insights into video performance across different content types.
Finally, although `groupby()` is very efficient at data aggregation, its performance can become slower if we include complicated custom aggregation functions. This trade-off between complexity and speed is an important consideration when implementing video analysis workflows, ensuring fast turnaround times.
Creating Dynamic Tables in Python A Step-by-Step Guide Using Pandas for Video Analysis Data - Updating Tables Dynamically with assign() and append()
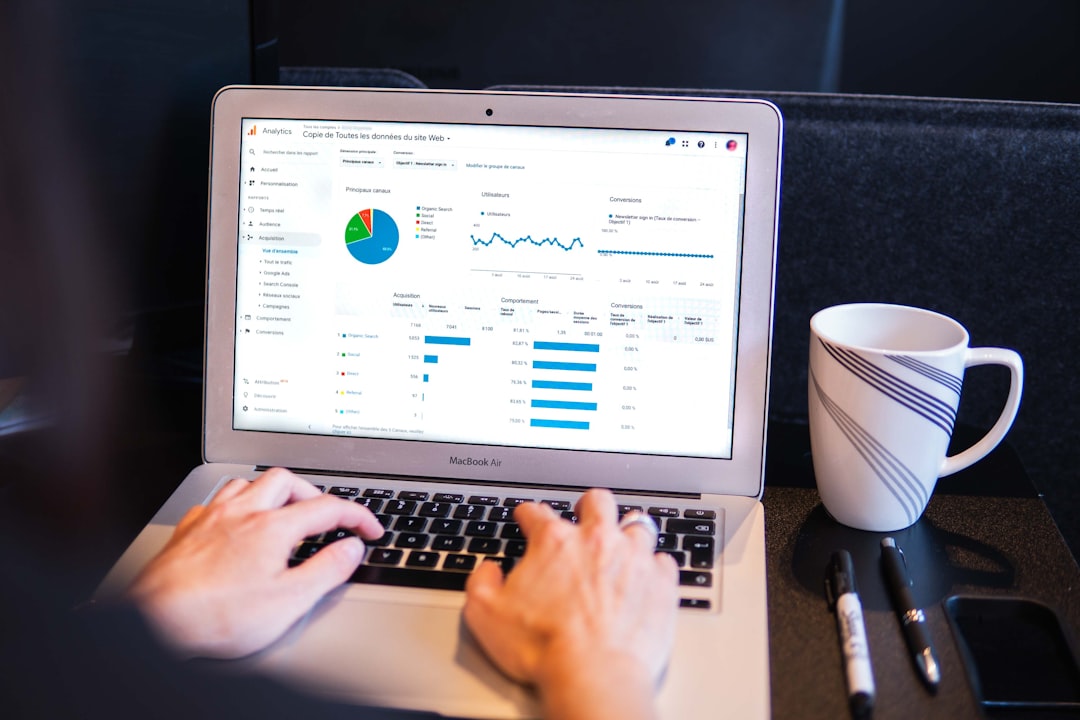
Pandas provides tools like `assign()` and `append()` to dynamically update DataFrames, which is crucial for building tables as you analyze video data. `Assign()` lets you add new columns to a DataFrame, whether based on existing data or calculations, without altering the original. This makes it a flexible choice for adding features or metrics derived from your analysis. However, `append()` is used to combine rows from different DataFrames. While seemingly straightforward, repeatedly appending in loops can cause a performance hit as Pandas generates a new DataFrame each time. To avoid this, a better practice is to store DataFrames in a list and then use `pd.concat()` to merge them at once, leading to substantial improvements, especially when working with sizable video analysis datasets. This process of dynamically updating the table allows for a more organized and efficient way to manage the metrics extracted from your video frames, making analysis smoother and deeper. While seemingly simple, understanding the nuances of how to best apply `assign()` and `append()` can really impact the efficiency and effectiveness of your analysis pipeline.
1. Pandas' `assign()` method provides a neat way to introduce new columns to a DataFrame, either by applying functions or using existing columns. This makes dynamic table updates possible without altering the original structure, resulting in cleaner and easier-to-read code.
2. While `append()` offers a straightforward way to add rows to a DataFrame, it's crucial to understand that it produces a new DataFrame, leaving the original untouched. This can be a drag on performance, particularly if it's used inside loops where repeated copying of large datasets can quickly exhaust available memory.
3. Unlike SQL tables, which have a predefined structure, Pandas allows for dynamic column additions or modifications on the fly, making it a flexible choice for exploratory analysis. However, without a consistent naming scheme, this flexibility can lead to confusion and difficulty in managing the DataFrame's structure.
4. `append()` is designed for stacking DataFrames vertically, ideal for progressively adding new video metrics over time. It's important to ensure column compatibility—data types and names must match to prevent unexpected outcomes or data loss during the concatenation process.
5. Both `assign()` and `append()` can handle operations across multiple rows or columns simultaneously (broadcasting), making data manipulation efficient and concise. However, packing too many operations into a single method can make it harder to understand the sequence of calculations, potentially leading to problems when maintaining the code.
6. `assign()` can be coupled with lambda functions to create new columns based on existing data, which enables dynamic updates depending on analysis findings. While powerful, this can hinder performance on very large datasets if not optimized properly.
7. Combining `assign()` and `append()` facilitates iterative analyses, where results from several analysis steps are combined and examined. This increases complexity, and it becomes vital to maintain detailed documentation of both the processing stages and the DataFrame's current state.
8. `append()` is frequently used with Python's list comprehensions for batch updates, often offering better memory management than looping with `append()`. Nevertheless, despite its efficiency, it's vital for developers to meticulously verify the accuracy of the data being aggregated to prevent errors during appends.
9. The synergy between `assign()` and `append()` improves data transformation workflows, especially in video analysis where maintaining an updated DataFrame is key for quick insights. However, the lack of built-in transaction management means simultaneous updates can accidentally lead to data integrity issues.
10. Overusing `append()` can slow down analysis, particularly when dealing with extensive DataFrames. It's generally a good idea to minimize `append()` calls within iterative processes and, instead, create a list of DataFrames that can be combined into a single DataFrame using `pd.concat()` at the very end.
Creating Dynamic Tables in Python A Step-by-Step Guide Using Pandas for Video Analysis Data - Summarizing Data Trends with pivot_table()
Pandas' `pivot_table()` function is a valuable tool for summarizing and analyzing trends in your video analysis data. It allows you to restructure your data into a more insightful format by aggregating information across different columns. You can tailor the table's structure by specifying which columns should be used as rows (`index`), columns (`columns`), and the data you want to summarize (`values`). This dynamic approach provides flexibility in how you view and understand your video data.
Further control over the analysis comes from the `aggfunc` parameter. It enables you to specify which aggregation function, like `mean`, `sum`, or `count`, you want to use when summarizing data. This offers a wide range of options for exploring different aspects of video engagement, viewership, or interaction.
Another practical advantage of `pivot_table()` is its ability to handle missing data (NaNs) via the `fill_value` parameter. This helps in managing real-world video datasets that often contain incomplete or missing information, making the analysis more robust.
While `pivot_table()` offers a powerful means to understand data trends within video analysis, it's essential to be aware of how it can potentially alter the data's original structure. Excessive use or misapplication of `pivot_table()` can make it harder to interpret the results or understand how they relate to the initial data. So, while helpful, it's important to use this function strategically to prevent confusion during the analysis process.
Pandas' `pivot_table()` function offers a way to create multi-layered summaries of video data, like examining viewership by video and user characteristics. This can help reveal complex trends that might be hidden in simpler analysis. While beneficial, it's crucial to realize that `pivot_table()` can automatically fill in missing values using functions like `mean` or `sum`. While convenient, this can subtly influence results, potentially leading to biased interpretations unless carefully considered.
By default, `pivot_table()` calculates the average (`mean`), but users can specify different summary functions, such as `count`, `sum`, or even create their own. This customizability is great, but it can make understanding the output more difficult if the functions aren't clearly documented. Restructuring large datasets with `pivot_table()` can make analysis faster and easier to understand, but it can also obscure the raw data. It's vital to maintain a clear link to the original dataset to avoid losing track of where the data came from.
A potential limitation is that `pivot_table()` can become computationally demanding with extremely large datasets, slowing down the process. Researchers need to consider their data before using this method, sometimes choosing simpler aggregations for large or complex datasets. Dealing with duplicated data is also handled through the `aggfunc` parameter, but this can lead to unexpected aggregation outcomes if the user is not careful and doesn't understand the data structure.
Once a dynamic table is created using `pivot_table()`, it can be exported into various formats, including Excel or CSV, making it easy to share with others. Nonetheless, users need to ensure that the export process doesn't compromise the table's structure and information integrity. `pivot_table()` doesn't just work with numbers; it can also summarize categorical data, like different video metadata, providing valuable insights into viewers' interactions and habits.
Understanding how to define the index and columns in `pivot_table()` is crucial as incorrect choices can lead to misleading summaries. Clear planning and careful consideration when setting up the table are essential for accurate representation of relationships. In video analysis, `pivot_table()` can be very useful for tracking metrics over time. By defining specific time frames, you can analyze changes in engagement, which can be helpful in guiding content decisions based on past viewer behaviour.
Creating Dynamic Tables in Python A Step-by-Step Guide Using Pandas for Video Analysis Data - Handling Missing Data in Video Analysis Results
Missing data is a common challenge in video analysis, often stemming from issues like camera malfunctions, objects obstructing the view, or errors during the process of segmenting the video. Pandas, a popular Python library for data manipulation, offers a range of techniques for handling these gaps, including removing rows with missing values (`dropna()`), filling in missing values with a chosen value or strategy (`fillna()`), or using interpolation techniques. Understanding the nature of missing data is important, and Pandas' `.isnull()` function helps you see how extensive the problem is.
Moreover, visualization tools can be useful. For example, heatmaps or scatterplots can help you spot patterns in the missing data. This visual information helps you choose the most appropriate way to handle these gaps, be it removing them or using methods like filling them with an average or median value (imputation). It's crucial to remember that the approach you take towards missing data can directly influence the reliability of your analysis, especially for applications that rely on insights derived from the video data such as object tracking or behavior prediction. Properly handling missing values is essential for ensuring that your analysis is accurate and produces reliable results. However, it is easy to introduce bias, and care must be taken to ensure any imputation technique doesn't skew the results of the analysis.
1. Missing data in video analysis can stem from various issues like camera glitches, objects blocking the view, or errors in how the video is processed into data. Recognizing the causes and how often data is missing is important because it can affect how reliable the analysis is overall.
2. Methods like imputation can help us deal with missing values, but the way we choose to fill in those gaps really influences the final results. Common approaches include replacing missing values with the average or using more advanced methods. However, these methods can introduce bias if we don't carefully consider how the data is normally distributed.
3. Simply removing rows with missing data, while easy, might lead to losing a significant amount of information, particularly with large datasets. Even if only a small portion of the data is missing, it can affect the outcome of the analysis. This trade-off emphasizes the importance of looking for better solutions that don't discard information.
4. The impact of missing data can also depend on what kind of video we're dealing with. For example, the effect of missing some frame information in a video with a lot of movement might be different compared to a video with mostly static scenes. Having a good grasp of the video content can guide us towards the best approach to handling missing data.
5. In video analysis where the data is processed in real-time, there can be delays in the data stream. When we look at the data, it may seem like frames are missing, but these gaps may not always be due to problems with the data. Instead, they may reflect the normal delays in how video data flows. This changes how engineers think about handling missing data in this context.
6. If we summarize the video analysis data without properly accounting for missing values, we could draw incorrect conclusions. This highlights the need to investigate different methods for filling in those gaps before we summarize the results. Using the wrong approach can hide patterns in how people engage with the video, so it's crucial to pick a good method.
7. Visual tools like heatmaps and graphs can help us understand where the missing data is. These visual cues can give insights into where the data is missing most frequently, helping us make better decisions about how to address it in the next steps of the analysis.
8. Some video analysis tasks are more tolerant to missing data than others. For instance, tracking trends over a longer time period may still provide valid results even if there are intervals with missing data. Researchers must think about which metrics matter most to the analysis when deciding how to deal with missing data.
9. There are now tools and libraries that work well with Pandas, offering features specifically designed to handle missing data. This can help to simplify the analysis process, and provide good solutions to the problem of missing data. But it's important for engineers to carefully evaluate these tools to make sure they are appropriate for the complexity and specific needs of their analysis.
10. Finally, it's very important to record how we handle the missing data. This makes it easier for other people to understand and replicate the analysis. If we don't manage missing data properly, it can affect the credibility of our dataset in the long run. This makes transparency in our analysis methods very important.
More Posts from whatsinmy.video: